運用保守を先回り
新しいETLのスタンダード
データ転送 (ETL) / マネージドデータ転送
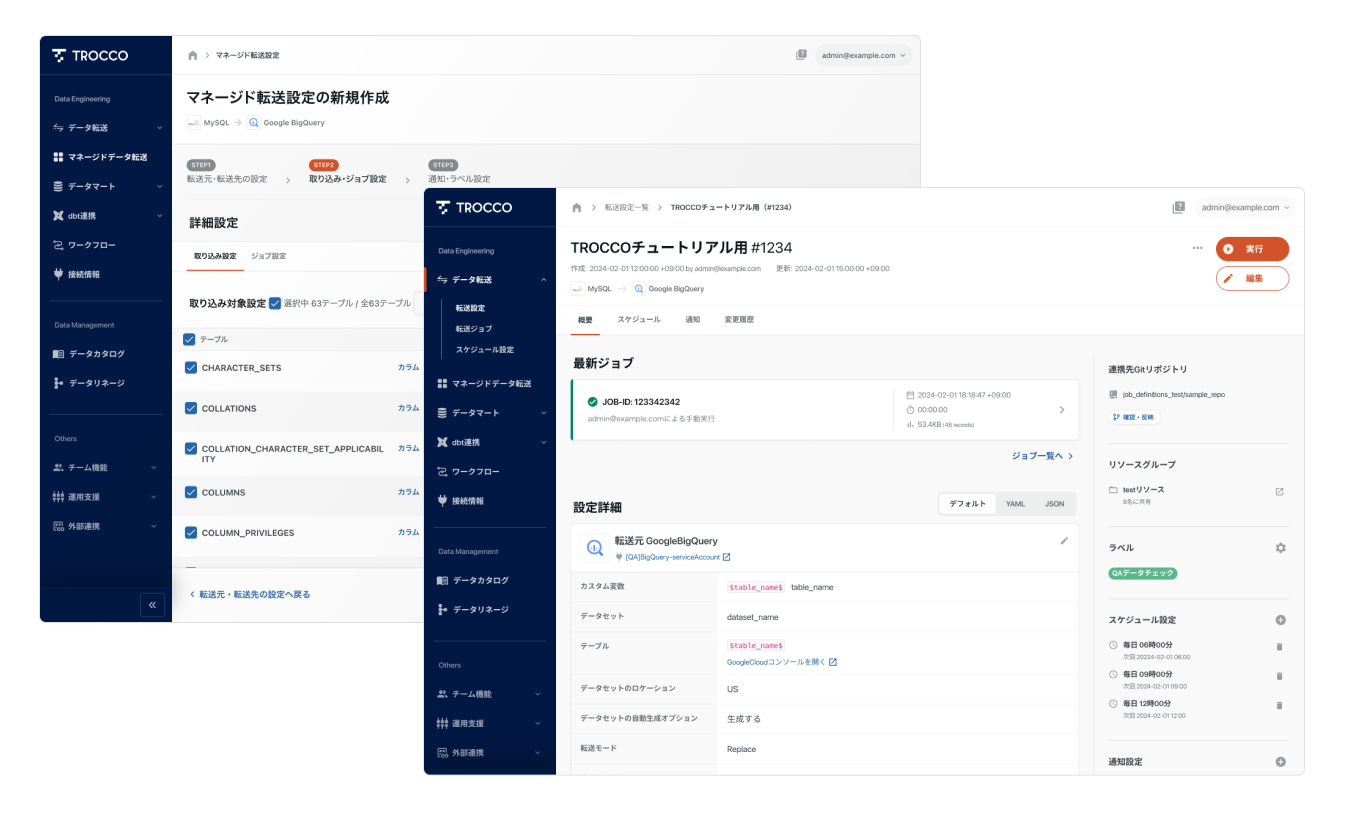
ETLパイプラインの構築、データソースの変更への追従、APIアップデートへの対応…
データ活用するための環境を構築し、維持していくには、多大な工数を要します。
そういった泥臭いタスクはTROCCO®におまかせください。
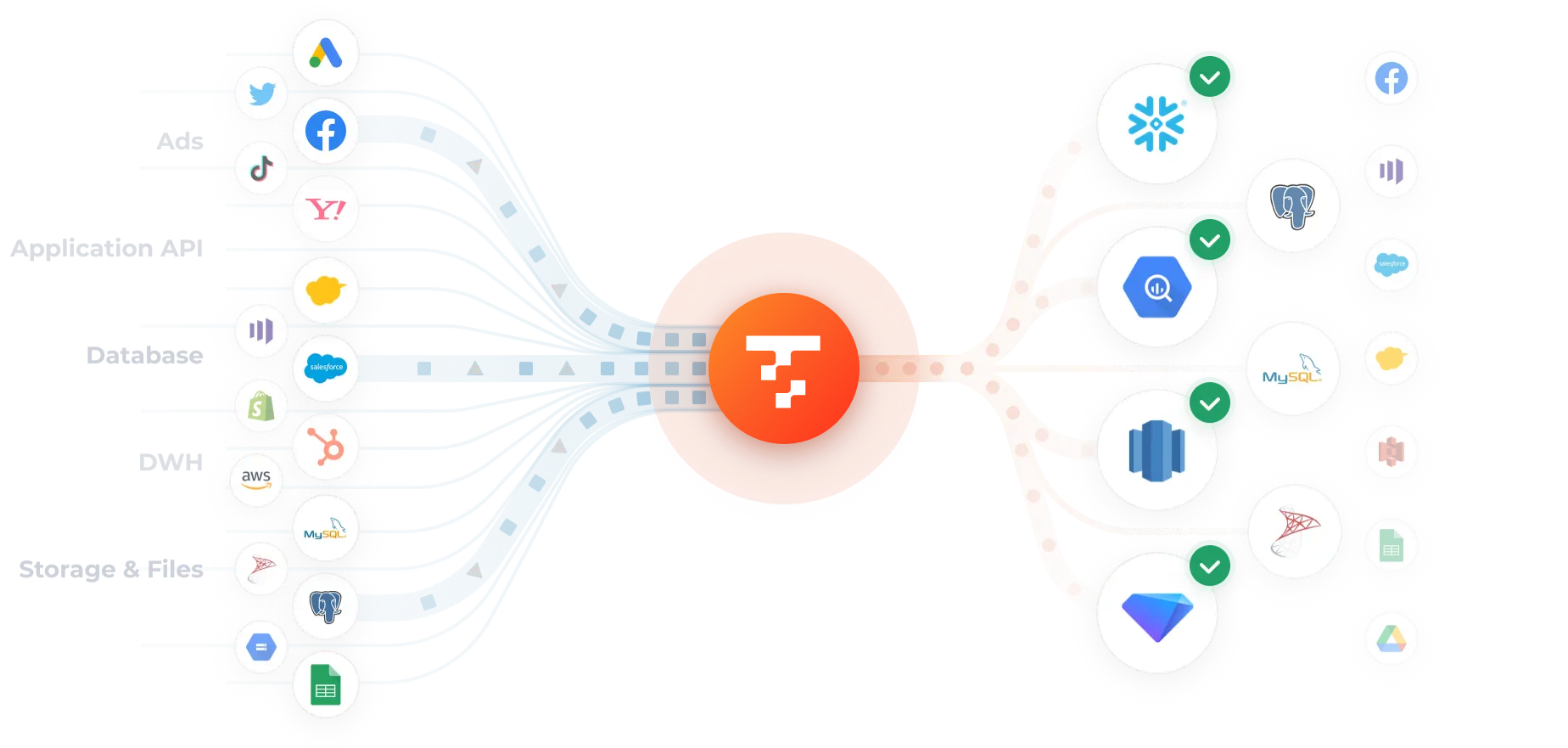
ETLではノーコードからプログラミング言語による柔軟な変換処理までカバー。
ELTの場合はdbt連携による精緻なデータモデリングに対応します。
CDC(変更データキャプチャ)形式のデータロードにも対応。
データソース側の変更をフルマネージドに追従します。
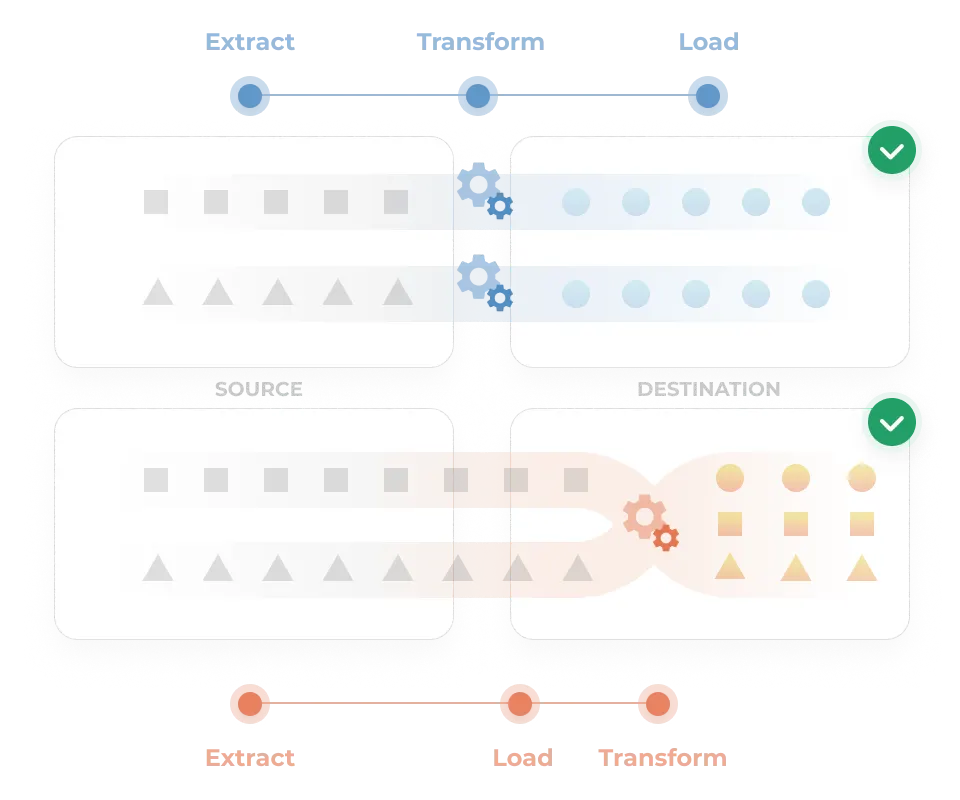
エンジニアリングのベストプラクティスを、データ基盤にも。
本格的な運用フェーズにも耐えうる多彩な機能が揃っています。
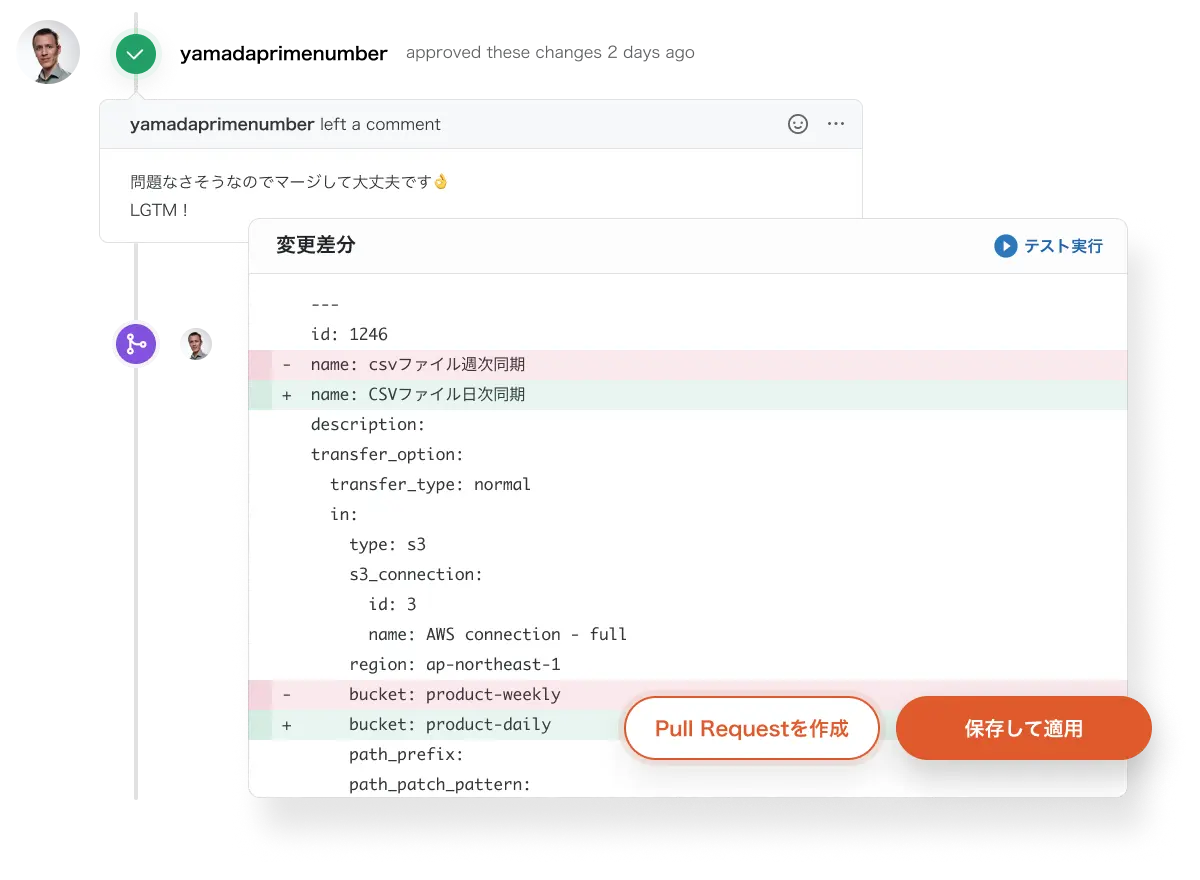
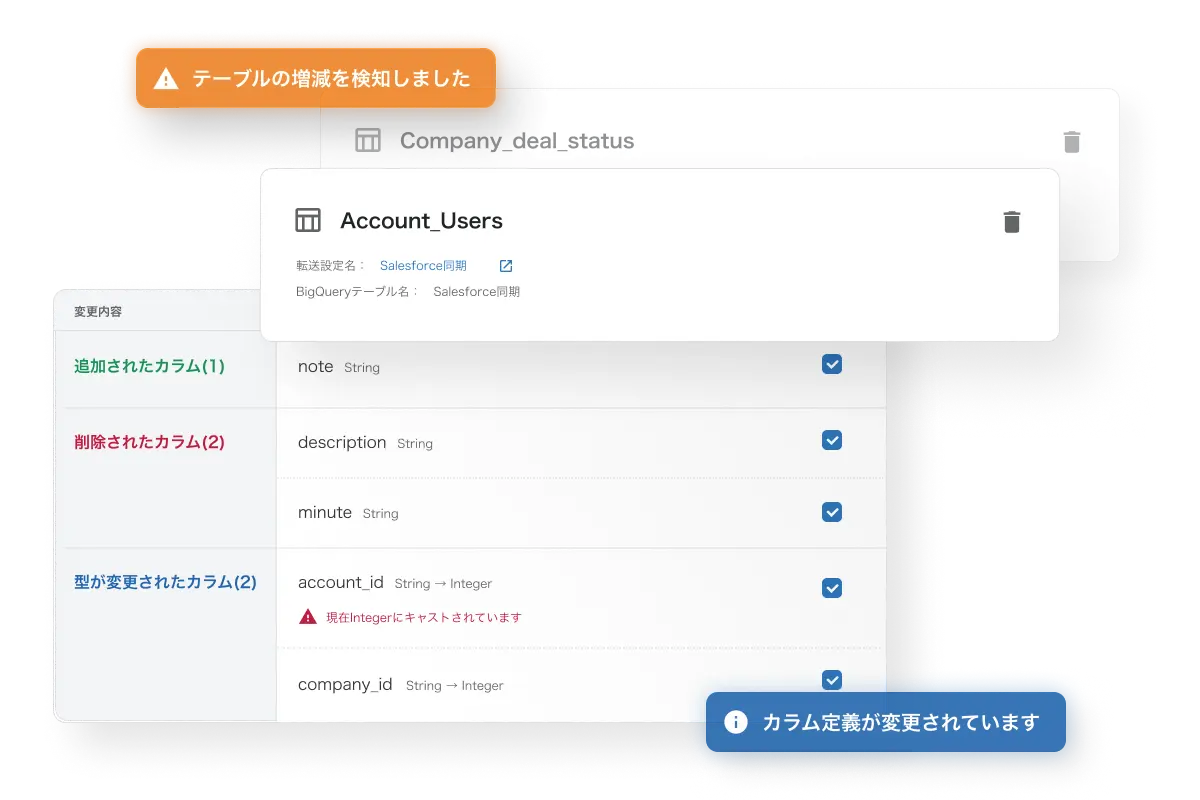
ETLパイプラインを構築すると、データソース側の列追加・テーブル追加・APIアップデートなどの対応が日々発生します。
ETLに標準搭載されているスキーマ変更検知・追従機能では、列の追加・削除・変更の追従が可能。マネージドデータ転送ではテーブルレベルの追加・削除に対する変更を追従することが可能です。
データソースのAPIアップデートに対する追従も、TROCCO®内部で自動的に行われます。
よくあるETL処理はGUIで簡単に設定。
複雑な処理が必要な場合は、プログラミングETLで対応可能です。
ニーズやリテラシーに応じて、データ整備・平準化を負担なく行うことができます。
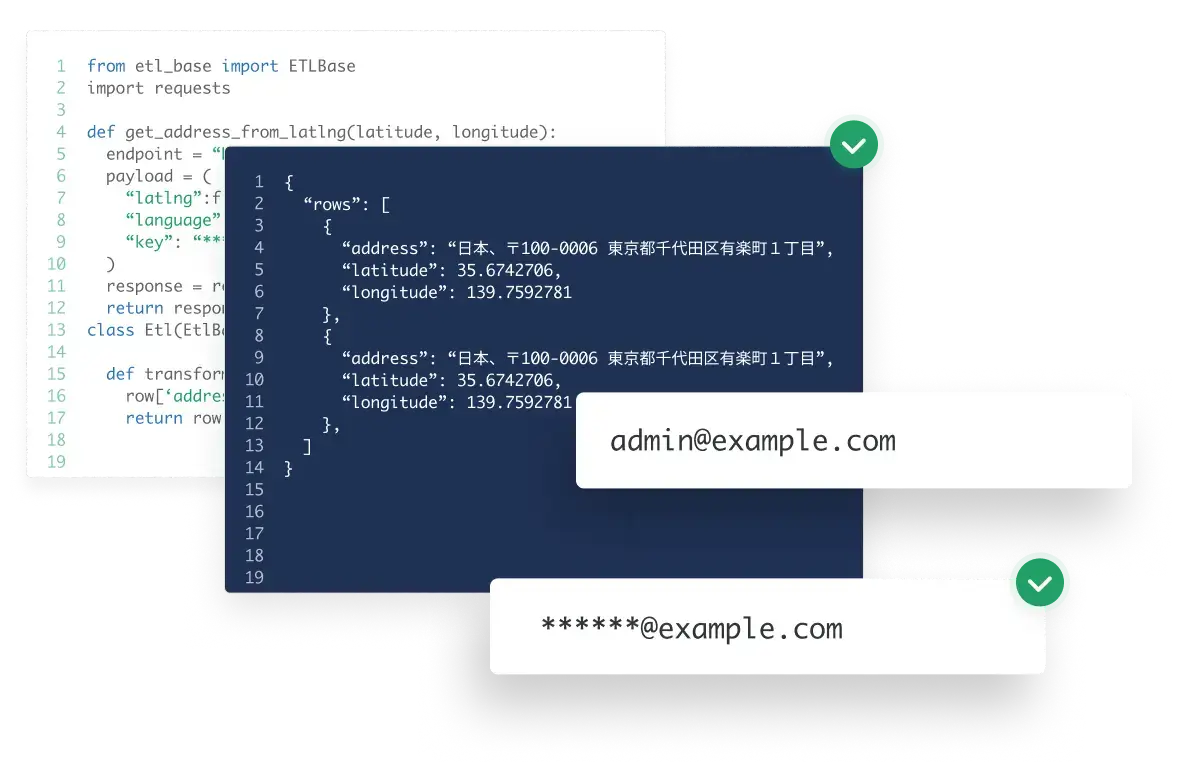
設定・運用時の細かいイライラを最小限に。
エンジニアが自ら使いたくなるように考え抜かれたUIは、データエンジニアリング上の各種タスクに対して「最短経路」を提供します。
BigQueryの分割テーブルや、クラスタリングテーブルの作成・更新に対応しています。
転送元がファイル形式の場合*、ファイル圧縮形式・フォーマット・スキーマ(データ型)を自動で推論。マッピングや型入力のコストを削減できます。
* Amazon S3、Google Spreadsheetsなど
転送元のJSON型データを展開し、転送先のカラムにマッピング可能です。
TROCCO®独自に提供するレポートテンプレートにより、広告系コネクタからのデータ抽出を効率化。 広告分析に最適なフィールドをサジェストします。
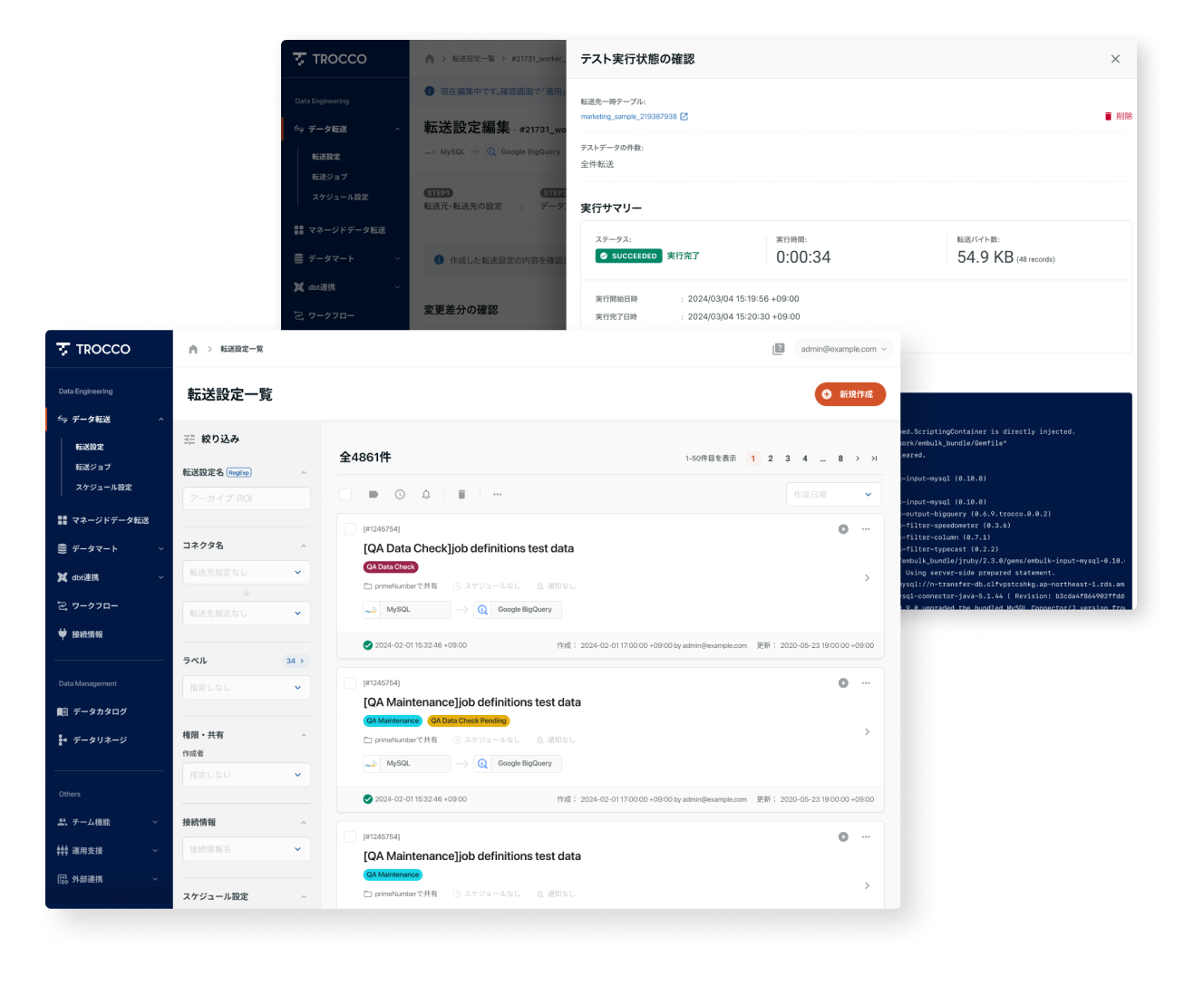
作成した転送設定*で問題なくジョブが実行できるか、本番環境に適応する前にテスト実行で確認することができます。
* 転送先BigQueryの場合のみ
ETLパイプラインの設定の各所にカスタム変数を埋め込み可能です。 手動再実行時などのバックフィル用途で利用できるほか、ループ実行などの柔軟な実行方法をサポートします。
SQLエディタで変換処理を書くだけで、DWH上のログをビジネス活用しやすい状態に整備
複雑なパイプラインもGUIで定義。データエンジニアに必要な接続先が豊富
DWH上に蓄積されたデータに対し、柔軟なテスト・検証が可能
Infrastructure as Codeをデータ基盤にも。外部ツールとのAPI連携も充実
通知や再実行など、データ基盤の運用に必要な支援機能を、エンジニア目線で開発
専用のSDKでWebサイトのログ・イベントを収集し、お好きなDWHに転送
大切なデータを扱うため、暗号化やIP制限などの機能を搭載
お客様専任の担当がつき、障害対応や運用をサポート
